DP-900:Azure 数据基础第一部分之核心数据概念
本文依据文末 Azure 参考资料进行翻译及整理,作学习及知识总结之用。
介绍常见的数据格式、工作负载,以及角色和服务。
1 核心数据概念
1.1 常用数据格式
数据是事实的集合,如用于记录信息的数字、描述和观察结果。组织这些数据的数据结构通常表示对组织很重要的实体(如:客户、产品、销售订单等)。每个实体通常具有一个或多个属性(如:客户可能有姓名、地址和电话号码等)。
数据可被分类为:结构化、半结构化和非结构化。
结构化数据
结构化数据是遵循固定模式的数据,因此所有数据都具有相同的字段或属性。结构化数据实体的模式通常是表格化的:即数据由一个或多个表表示,表由行和列(行表示数据实体的实例,列表示数据实体的属性)来组成。
例如,下图展示了 Customer 和 Product 数据实体的表格化表示。
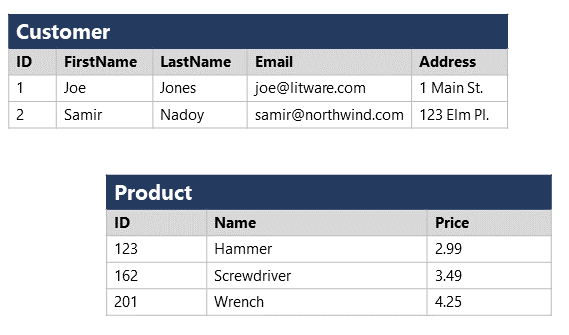
结构化数据通常存储在数据库中,其中多个表可以通过使用关系模型中的键值来相互引用。
半结构化数据
半结构化数据是具有某种结构的信息,但它允许实体实例之间存在一些变化。例如,虽然大多数客户可能只有一个电子邮件,但有些可能有多个,有些可能一个都没有。
半结构化数据的一种常见格式是 JavaScript Object Notation(JSON)。下面的示例显示了一对表示客户信息的 JSON 文档。每个客户文档都包含地址和联系信息,但具体字段因客户而异。
// Customer 1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
// Customer 2
{
"firstName": "Samir",
"lastName": "Nadoy",
"address":
{
"streetAddress": "123 Elm Pl.",
"unit": "500",
"city": "Seattle",
"state": "WA",
"postalCode": "98999"
},
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
JSON 只是可以表示半结构化数据的众多方式之一。这里的重点不是提供对 JSON 语法的详细检查,而是说明半结构化数据表示的灵活性。
非结构化数据
并非所有数据都是结构化或半结构化的。例如,文档、图像、音频和视频数据以及二进制文件可能没有特定的结构。这种数据被称为非结构化数据。
数据存储
因数据有结构化、半结构化和非结构化这三种类型,所以常用的数据存储可归为两大类:数据库和文件存储。
1.2 文件存储
用于存储数据的特定文件格式取决于许多因素,包括:
- 存储的数据类型(结构化、半结构化或非结构化);
- 需要读取、写入和处理数据的应用程序和服务;
- 需要人类可读的数据文件,或为有效存储和处理而优化的数据文件。
下面讨论一些常见的文件格式。
分隔的文本文件
数据通常以带有特定字段分隔符和行终止符的纯文本格式存储。最常见的分隔数据格式是字段由逗号分隔,行由回车/换行符终止。第一行可以是值也可以是字段名称。
其他常见的格式包括制表符分隔 (TSV) 和空格分隔(其中制表符或空格用于分隔字段),以及为每个字段分配固定数量字符的固定宽度数据。
对于需要以人类可读格式访问的各种应用程序和服务的结构化数据,分隔文本是一个不错的选择。
以下示例以逗号分隔格式显示一组客户数据:
FirstName,LastName,Email
Joe,Jones,joe@litware.com
Samir,Nadoy,samir@northwind.com
JSON
JSON 是一种普遍存在的格式,其中使用分层文档模式来定义具有多个属性的数据实体(对象)。JSON 中的每个属性可以是一个对象(或对象的集合);使 JSON 成为一种适用于结构化和半结构化数据的灵活格式。
如下示例显示了一个包含客户集合的 JSON 文档。每个客户都有三个属性(名字、姓氏和联系人),而联系人属性可包含多个联系方式。
{
"customers": [
{
"firstName": "Joe",
"lastName": "Jones",
"contact": [
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
},
{
"firstName": "Samir",
"lastName": "Nadoy",
"contact": [
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
]
}
XML
XML 是一种人类可读的数据格式,在 1990 年代和 2000 年代流行。目前,它在很大程度上已被不那么冗长的 JSON 格式所取代,但仍有一些系统在使用 XML 来表示数据。
XML 使用括在尖括号 (<../>) 中的标签来定义元素和属性,示例如下:
<Customers>
<Customer name="Joe" lastName="Jones">
<ContactDetails>
<Contact type="home" number="555 123-1234"/>
<Contact type="email" address="joe@litware.com"/>
</ContactDetails>
</Customer>
<Customer name="Samir" lastName="Nadoy">
<ContactDetails>
<Contact type="email" address="samir@northwind.com"/>
</ContactDetails>
</Customer>
</Customers>
BLOB
最终,所有文件都存储为二进制数据(1 和 0),但在上面讨论的人类可读格式中,二进制数据的字节被映射到可打印字符(通常通过字符编码方案,如 ASCII 或 Unicode)。然而,特别是对于非结构化数据的一些文件格式,将数据存储为必须由应用程序解释和呈现的原始二进制文件。以二进制形式存储的常见数据类型包括图像、视频、音频和特定于应用程序的文档。
数据专业人员通常将该类数据文件称为 BLOB(Binary Large Objects,二进制大对象)。
优化的文件格式
虽然结构化和半结构化数据的人类可读格式可能很有用,但它们通常没有针对存储空间或处理进行优化。随着时间的推移,已经开发出一些支持压缩、索引以及高效存储和处理的专用文件格式。
一些常见的优化文件格式,包括 Avro、ORC 和 Parquet:
Avro 是一种基于行的格式。其由 Apache 创建。每条记录都包含一个消息头,该消息头描述了记录中数据的结构。此消息头存储为 JSON,数据存储为二进制。应用程序使用消息头中的信息来解析二进制数据并提取其中包含的字段。Avro 是一种很好的格式,可用于压缩数据并最大限度地减少存储和网络带宽需求。
ORC(Optimized Row Columnar format,优化行列格式)将数据组织成列而不是行。其由 HortonWorks 开发,用于优化 Apache Hive 中的读写操作(Hive 是一个数据仓库系统,支持对大型数据集进行快速汇总和查询)。ORC 文件包含一组数据条,每个数据条保存一列或多列数据。数据条包含数据条中行的索引、每行的数据以及用于保存每列的统计信息(计数、总和、最大值、最小值等)的页脚。
Parquet 是另一种列数据格式,其由 Cloudera 和 Twitter 创建。Parquet 文件包含行组,每列的数据一起存储在同一行组中,每个行组包含一个或多个数据块。Parquet 文件包含描述在每个块中找到的行集的元数据。应用程序可以使用此元数据快速定位给定行集的正确块,并检索这些行的指定列中的数据。Parquet 擅长高效地存储和处理嵌套数据类型,支持非常有效的压缩和编码方案。
1.3 数据库
数据库用于定义可以存储和查询数据的中央系统。简单来说,存储文件的文件系统是一种数据库;但是当我们在专业数据上下文中使用该术语时,我们通常指的是用于管理数据记录而非文件的专用系统。
关系型数据库
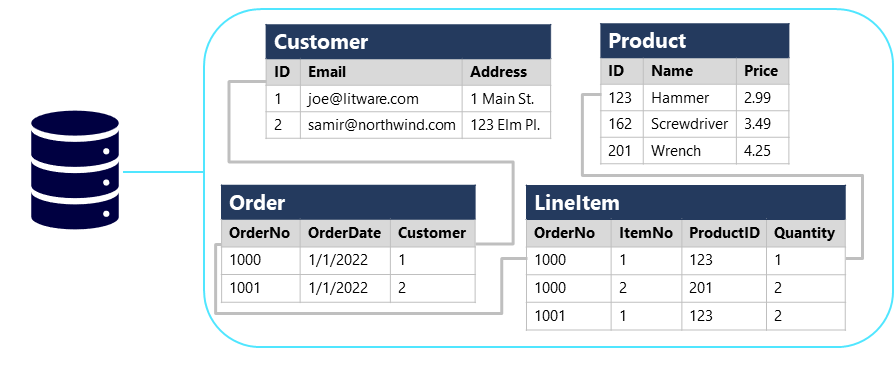
关系型数据库通常用于存储和查询结构化数据。数据存储在代表实体的表中,例如客户、产品或销售订单。实体的每个实例都分配有一个唯一标识它的主键,这些键用于引用其它表中的实体实例。例如,可以在销售订单记录中引用客户的主键来指示哪个客户下的订单。使用键来引用数据实体可以使关系型数据库变得规范化,这可以避免重复值。例如,单个客户的详细信息仅存储一次,而不是针对客户下的每个销售订单都存储一次。这些表是使用基于 ANSI 标准的 SQL 语言 (Structured Query Language,结构化查询语言) 来管理和查询的,因此在多个数据库系统中是类似的。
非关系型数据库
非关系数据库是不对数据应用关系模式的数据管理系统。非关系型数据库通常被称为 NoSQL 数据库(尽管有些支持 SQL 语言的变体)。
常用的非关系型数据库有四种常见类型:
- 键值数据库,其中每条记录都由唯一键和关联值组成,可以是任何格式。

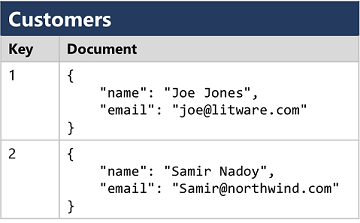
- 文档数据库,这是一种特定形式的键值数据库,其中值是 JSON 文本(系统已对其进行了优化以解析和查询)。
- 列族数据库,它存储包含行和列的表格数据,但您可以将列划分为称为列族的组。每个列族包含一组逻辑上相关的列。

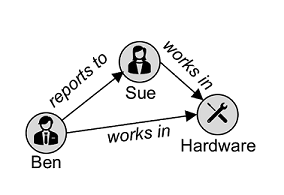
- 图数据库,将实体存储为具有连接的节点,以定义它们之间的关系。
1.4 事务数据处理
事务数据处理系统是大多数人认为的业务计算的主要功能。事务系统记录了组织想要跟踪的封装特定事件的事务。事务可以是金融交易,例如银行系统中账户之间的资金流动,也可以是零售系统的一部分,跟踪客户对商品和服务的支付。可将事务视为一个小的、离散的工作单元。
交易系统通常是大容量的,有时在一天内处理数百万笔交易。正在处理的数据必须可以非常快速地访问。事务系统执行的工作通常称为 OLTP (Online Transactional Processing,联机事务处理)。
![]()
OLTP 解决方案依赖于数据库系统,其中数据存储针对读取和写入操作进行了优化,以支持创建、检索、更新和删除数据记录(通常称为 CRUD 操作)的事务工作负载。这些操作使用了事务,以确保存储在数据库中数据的完整性。为此,OLTP 系统确保了支持所谓 ACID 语义的事务:
原子性 - 每个事务都被视为一个单元,完全成功或完全失败。例如,有一个事务为从一个账户扣款和到一个账户的等额打款,这两项操作必须同时执行。如果其中一个操作不能完成,那么另一个也必须失败。
一致性 - 事务只能将数据库中的数据从一种有效状态转移到另一种有效状态。借用上面的扣款和入账示例,交易的完成状态必须反映资金从一个账户转移到另一个账户。
隔离性 - 并发事务不能相互干扰,并且必须有一致的数据库状态。例如,虽然将资金从一个账户转移到另一个账户的事务正在进行中,但检查这些账户余额的另一个事务必须返回一致的结果。余额检查事务不能为付款账户返回一个转账前的余额,而为收款账户返回一个到账后的余额。
持久性 - 当一个事务被提交时,它将保持提交状态。账户转账事务完成后,修改后的账户余额会被持久化,这样即使数据库系统被关闭,再次开启时也会反映提交的事务。
OLTP 系统通常用于支持处理业务数据的实时应用程序,通常称为业务线 (LOB) 应用程序。
1.5 分析数据处理
分析数据处理通常会使用存储大量历史数据或业务指标的只读系统。分析可以基于给定时间点的一个数据快照或一组快照来进行。
分析处理系统的具体细节可能因解决方案而异,但企业级分析系统的通用架构如下图所示:

- 数据文件可以存储在中央数据湖中以供分析。
- 提取、转换和加载 (ETL) 过程将数据从文件和 OLTP 数据库复制到针对读取活动进行了优化的数据仓库中。通常,数据仓库模式会基于包含您要分析的数值(例如,销售额)的事实表,以及表示您要衡量它们的实体(例如,客户或产品)的相关维度表。
- 数据仓库中的数据可以聚合并加载到联机分析处理 (OLAP) 模型或多维数据集中。事实表的聚合数值(度量)是为了维度表中维度的交集计算。例如,销售收入可能按日期、客户和产品来累加。
- 数据湖、数据仓库和分析模型中的数据可被查询以生成报告、可视化图表和仪表板。
数据湖在大规模数据分析处理场景中很常见,需要收集和分析大量基于文件的数据。
数据仓库是一种将数据存储在关系模式中的既定方式,该模式针对读取操作进行了优化,主要是支持报告和数据可视化的查询。数据仓库模式可能需要对 OLTP 数据源中的数据进行一些逆规范化(引入一些重复以使查询执行得更快)。
OLAP 模型是一种聚合类型的数据存储,其针对分析工作负载进行了优化。
数据聚合在不同层次的维度上,使您能够查看多个层次级别的聚合;例如,按区域、城市或单个地址查找总销售额。由于 OLAP 数据是预先聚合的,因此可以快速运行返回其包含的摘要的查询。
不同类型的用户可能在整个架构的不同阶段执行数据分析工作。例如:
- 数据科学家可能会直接使用数据湖中的数据文件来探索和建模数据。
- 数据分析师可能直接在数据仓库中查询表以生成复杂的报告和可视化。
- 业务用户可能会以报告或仪表板的形式在分析模型中使用预先聚合的数据。
2 数据角色和服务
数据专业人员在管理、使用和控制数据时通常扮演不同的角色。在本模块中,将介绍数据专业人员的各种角色、与这些角色相关的任务和职责,以及用于执行这些任务的 Azure 服务。
2.1 数据世界中的角色
管理、控制和使用数据涉及各种各样的角色。有些角色是面向业务的,有些更多涉及工程,有些专注于研究,有些是结合数据管理不同方面的混合角色。您的组织可能以不同的方式定义角色,或者给它们不同的名称,但本单元中描述的角色涵盖了最常见的任务和职责划分。
大多数组织中处理数据的三个关键角色是:
- 数据库管理员,负责管理数据库、为用户分配权限、存储数据的备份并在发生故障时恢复数据。
- 数据工程师,负责管理整个组织的数据集成基础设施和流程,应用数据清理协程,识别数据治理规则,并实现在系统之间传输和转换数据的流水线。
- 数据分析师,负责探索和分析数据以创建可视化图表,使组织能够做出明智的决策。
工作角色定义了不同的任务和职责。但在某些组织中,同一个人可能会担任多个角色。
DBA(数据库管理员)
数据库管理员负责 On-Premise 或托管在云上的数据库系统的设计、实施和维护。他们负责数据库的整体可用性和性能优化。他们与利益相关者合作,以实施备份和恢复计划的规则、工具和流程,以便在自然灾害或人为错误后恢复。
数据库管理员还负责管理数据库中数据的安全性,为数据授权,授予或撤销用户的访问权限。
数据工程师
数据工程师与利益相关者合作设计和实施与数据相关的工作负载,包括数据提取管道、清理和转换活动以及用于分析工作负载的数据存储。他们使用广泛的数据平台技术,包括关系型和非关系型数据库、文件存储和数据流。
他们还负责确保维护云上以及自 On-Premise 到云上的各种存储的数据的隐私。
数据分析师
数据分析师使企业能够最大化其数据资产的价值。他们负责探索数据以找到趋势和关联性,设计和构建分析模型,并通过报告和可视化图表实现高级分析功能。
数据分析师根据业务需求将原始数据处理成相关的洞察力。
此处描述的角色代表了大多数大中型组织中与数据相关的关键角色。还有其它与数据相关的角色这里没有提到,比如数据科学家和数据架构师;还有其他与数据打交道的技术专业人员,包括应用程序开发人员和软件工程师。
2.2 数据服务
下面介绍 Azure 提供的一些最常用的数据云服务。
Azure SQL
Azure SQL 是基于 Microsoft SQL Server 数据库引擎的一系列关系型数据库解决方案的统称。特定的 Azure SQL 服务包括:
- Azure SQL Database - 完全托管的平台即服务 (PaaS) 数据库。
- Azure SQL Managed Instance - 具有自动维护功能的 SQL Server 托管实例,比 Azure SQL Database 拥有更灵活的配置,但所有者需要承担更多的管理责任。
- Azure SQL VM - 安装了 SQL Server 的虚拟机,可实现最大的可配置性并承担全部管理责任。
数据库管理员通常预配和管理 Azure SQL 数据库系统,以支持需要存储事务数据的业务线 (LOB,Line of Business) 应用程序。
数据工程师可以使用 Azure SQL 数据库系统作为管道的数据源,这些管道执行提取、转换和加载 (ETL) 操作以将事务数据提取到分析系统中。
数据分析师可以直接查询 Azure SQL 数据库以创建报告,但在大型组织中,这些数据通常与分析数据存储中的其它数据相结合,以支持企业分析。
用于开源关系数据库的 Azure Database
Azure 提供诸多流行开源关系型数据库的托管服务,包括:
- Azure Database for MySQL - 一个易于使用的开源数据库管理系统,通常用于 Linux、Apache、MySQL 和 PHP (LAMP) 技术栈应用程序。
- Azure Database for MariaDB - 一种较新的数据库管理系统,由 MySQL 的原始开发人员创建。该数据库引擎已被重写并针对性能作了优化。 MariaDB 提供与 Oracle 数据库的兼容性。
- Azure Database for PostgreSQL - 一种混合关系对象数据库。您可以将数据存储在关系表中,但 PostgreSQL 数据库还允许存储自定义数据类型,以及它们自己的非关系属性。
Azure Cosmos DB
Azure Cosmos DB 是一个全球规模的非关系型 (NoSQL) 数据库,它支持多个应用程序接口 (API),使你能够以 JSON 文档、键值对、列族和图形的形式存储和管理数据。
Azure Storage
Azure 存储是一项核心 Azure 服务,可让您将数据存储在:
- Blob containers - 可扩展、经济高效的二进制文件存储。
- File shares - 网络文件共享,例如您通常在公司网络中找到的文件。
- Tables - 需要快速读写数据的应用程序的键值存储。
数据工程师使用 Azure Storage 来托管数据湖 - 具有分层命名空间的 blob 存储,使文件能够在分布式文件系统的文件夹中组织。
Azure Data Factory
Azure Data Factory 是一个可让你定义和调度数据流水线以传输和转换数据的 Azure 服务。您可以将流水线与其他 Azure 服务集成,使您能够从云数据存储中提取数据,以及使用云上的计算服务处理数据,并将结果保存在另一个数据存储中。
数据工程师使用 Azure Data Factory 构建 ETL(提取、转换和加载)解决方案,这些解决方案使用来自整个组织的事务系统的数据来填充分析数据存储。
Azure Synapse Analytics
Azure Synapse Analytics 是一个全面、统一的数据分析解决方案,它为多种分析功能提供单一服务接口,包括:
- 流水线 - 基于与 Azure Data Factory 相同的技术。
- SQL - 一种高度可扩展的 SQL 数据库引擎,针对数据仓库工作负载进行了优化。
- Apache Spark - 一个开源分布式数据处理系统,支持多种编程语言和 API,包括 Java、Scala、Python 和 SQL。
- Azure Synapse Data Explorer - 一种高性能数据分析解决方案,针对使用 Kusto 查询语言 (KQL) 实时查询日志和遥测数据进行了优化。
数据工程师可以使用 Azure Synapse Analytics 创建统一的数据分析解决方案,通过单一服务将数据提取管道、数据仓库存储和数据湖存储结合起来。
数据分析师可以通过交互式 Notebook 使用 SQL 和 Spark 池来探索和分析数据,并利用与 Azure 机器学习和 Microsoft Power BI 等服务的集成来创建数据模型并从数据中提取洞察力。
Azure Databricks
Azure Databricks 是流行的 Databricks 平台的 Azure 集成版本,它将 Apache Spark 数据处理平台与 SQL 数据库语义和集成管理界面相结合,以实现大规模数据分析。
数据工程师可以使用现有的 Databricks 和 Spark 技能在 Azure Databricks 中创建分析数据存储。
数据分析师可以使用 Azure Databricks 中的原生 Notebook 支持来在 Web 界面中查询和查看数据视图。
Azure HDInsight
Azure HDInsight 为流行的 Apache 开源大数据处理技术提供 Azure 托管的集群,包括:
- Apache Spark - 一个开源分布式数据处理系统,支持多种编程语言和 API,包括 Java、Scala、Python 和 SQL。
- Apache Hadoop - 一个分布式系统,它使用 MapReduce 作业跨多个集群节点有效地处理大量数据。 MapReduce 作业可以用 Java 编写,也可以通过 Apache Hive(一种在 Hadoop 上运行的基于 SQL 的 API)等接口进行抽象。
- Apache HBase - 一个用于大规模 NoSQL 数据存储和查询的开源系统。
- Apache Kafka - 用于数据流处理的消息组件。
- Apache Storm - 一个通过 spout 和 bolts 拓扑进行实时数据处理的开源系统。
数据工程师可以使用 Azure HDInsight 来支持依赖多种开源技术的大数据分析工作负载。
Azure Stream Analytics
Azure 流分析是一个实时流处理引擎,它从输入中捕获数据流,从输入流中应用查询来提取和操作数据,并将结果写入输出以进行分析或进一步处理。
数据工程师可以将 Azure Stream Analytics 整合到数据分析体系结构中,这些体系结构捕获流数据以将其引入分析数据存储或进行实时可视化。
Azure Data Explorer
Azure Data Explorer 是一个独立的服务,它提供与 Azure Synapse Analytics 中的 Azure Synapse Data Explorer 运行时相同的高性能日志和遥测数据查询能力。
数据分析师可以使用 Azure Data Explorer 查询和分析包含时间戳属性的数据,例如通常在日志文件和物联网 (IoT) 遥测数据中找到的数据。
Microsoft Purview
Microsoft Purview 为企业范围的数据治理和可发现性提供了解决方案。您可以使用 Microsoft Purview 创建数据地图并跨多个数据源和系统跟踪数据沿袭,使您能够找到可靠的数据进行分析和报告。
数据工程师可以使用 Microsoft Purview 在整个企业中实施数据治理,并确保用于支持分析工作负载的数据的完整性。
Microsoft Power BI
Microsoft Power BI 是一个用于分析数据建模和报告展示的平台,数据分析师可以使用它来创建和共享交互式数据可视化报告。Power BI 报表可使用 Power BI Desktop 应用程序创建,然后通过基于 Web 的报表发布到 Power BI 服务以及 Power BI 移动应用中。
参考资料
[1] Exam DP-900: Microsoft Azure Data Fundamentals - learn.microsoft.com

相关文章
评论
 正在加载评论......
正在加载评论......