Neo4j 初探
Neo4j 使用 Java 和 Scala 语言编写,是一种专门为处理图数据而设计的开源数据库管理系统,其通过节点(Node)、关系(Relationship)和属性(Property)直观地表示数据,能够以高效的方式存储和查询复杂关系网络。Neo4j 特别适用于涉及连接关系的场景(如社交网络、推荐系统和知识图谱等)。除了具有图数据库的核心特性之外,Neo4j 还支持事务、集群化部署和运行时容错。
本文首先会介绍一下 Neo4j 的基础知识,然后以实例的方式介绍 Neo4j 基本功能的使用。
下面即以「图」的方式介绍一下 Neo4j:

上图中的圆圈即为节点,带有箭头的连线即为关系,圆圈右上角的方框可以看作是节点的标签以用于对节点作分组或标记。从上图可以看到:
- Neo4j 是一个图数据库;
- Neo4j 拥有 neo4j.com;
- Neo4j 由 Emil 所创建,且 Emil 在 Neo4j 工作;
- Neo4j 公司位于伦敦。
有了对图和 Neo4j 的第一印象后,接下来重点介绍一下 Neo4j 的基础知识,然后以实例的方式对 Neo4j 基础特性进行初步使用。
1 Neo4j 基础知识
介绍 Neo4j 的基础概念与特定术语之前,先放一张「吴京参演《战狼 II》的实例图」,这样在介绍概念时结合该实例图进行对比说明即可以有更直观的理解。

1.1 核心概念
节点(Node)、关系(Relationship)和属性(Property)是 Neo4j 用于表示事物及其联系的核心概念。
属性是对节点或关系进行描述的键值对信息。
节点用于表示实体,如:产品、车、位置等都可以是一个节点。节点可以使用标签(Label)来进行分组。节点还可以拥有多个属性。
关系用于连接两个节点,用于表示两个节点之间的联系,关系有且只有一个类型(Type)且关系是有方向的。关系也可以拥有属性,用于表示关系的额外信息。
下面对照本节开始处的「吴京参演《战狼 II》实例图」来解释这三个概念。图中的圆圈即为节点,箭头即为关系,圆圈和箭头下面方框中的信息即为属性。图中有两个节点,一个是吴京,一个是《战狼 II》。吴京拥有一个标签(演员),《战狼 II》拥有两个标签(电影,动作片)。吴京拥有两个属性(国籍:中国,出生年份:1974),《战狼 II》也拥有两个属性(名称:战狼 Ⅱ,发行年份:2017)。两个节点之间有一条带方向的箭头即是关系,该关系的类型是「参演了」,该关系拥有一个属性(参演角色:冷峰)。
1.2 数据建模
数据建模是指将实际业务中的实体及其之间的联系映射为图数据库中的节点、关系和属性。
数据建模的一个黄金法则如下图所示:

即节点使用名词,关系使用动词。
1.3 Cypher
Cypher 是 Neo4j 专为操作图数据库设计的一种声明式语言,其允许我们使用包含括号、破折号、箭头等符号的语法来表示和操作数据。该查询语言与 SQL 类似,但针对图数据库作了特定优化。
针对本节开始处的「吴京参演《战狼 II》实例」,可以使用如下 Cypher 语句进行数据创建:
CREATE
(a:Actor {name: "吴京", nationality: "中国", yearOfBirth: 1974}),
(m:Movie {name: "战狼 Ⅱ", releasedAt: 2017}),
(a)-[r:ACTED_IN {role: "冷峰"}]->(m)
上述 Cypher 语句相当于下面三条语句,其创建了演员(Actor)和电影(Movie)两个节点,并针对这两个节点创建了「演员 - 参演 -> 电影」这一关系:
CREATE (a:Actor {name: "吴京", nationality: "中国", yearOfBirth: 1974})
CREATE (m:Movie {name: "战狼 Ⅱ", releasedAt: 2017})
CREATE (a:Actor)-[r:ACTED_IN {role: "冷峰"}]->(m:Movie)
这里的圆括号((...))表示节点,圆括号内的花括号表示节点的属性({...}),破折号、方括号和箭头表示关系(-[...]->),方括号内的花括号表示关系的属性({...}),而a、m 和 r 是指向节点 Actor、Movie 和关系 ACTED_IN 的变量。
若想从刚刚创建的数据中找出《战狼 Ⅱ》的参演演员名字和参演角色,可以使用如下 Cypher 语句来实现:
// 从数据库中找出所有「演员 - 参演 -> 电影」的模式
MATCH (a:Actor)-[r:ACTED_IN]->(m:Movie)
// 然后根据电影名称进行筛选
WHERE m.name = "战狼 Ⅱ"
// 指定返回值
RETURN a.name AS actor, r.role AS role
对比关系型数据库的 SQL,可以看到 Cypher 的 MATCH 相当于 SQL 的 FROM/JOIN,WHERE 相当于 SQL 的 WHERE,RETURN 相当于 SQL 的 SELECT。
2 Neo4j 初步使用
上面介绍了 Neo4j 的基础概念,下面开始动手在本地安装一个 Neo4j 实例,然后使用 Cypher 进行数据创建和查询。
2.1 Neo4j Desktop 安装
想在本地安装和使用 Neo4j,最简单的方式是安装「Neo4j Desktop」。Neo4j Desktop 内置 Neo4j Server,且提供可视化管理界面,支持连接本地和远程 Neo4j 数据库。此外 Neo4j Desktop 还内置 Neo4j Browser 和 Neo4j Bloom,可以进行 Cypher 查询和可视化数据操作。
Neo4j Desktop 安装完成后,打开它,然后新建一个项目 test,并在该项目下新建一个 Local DBMS:
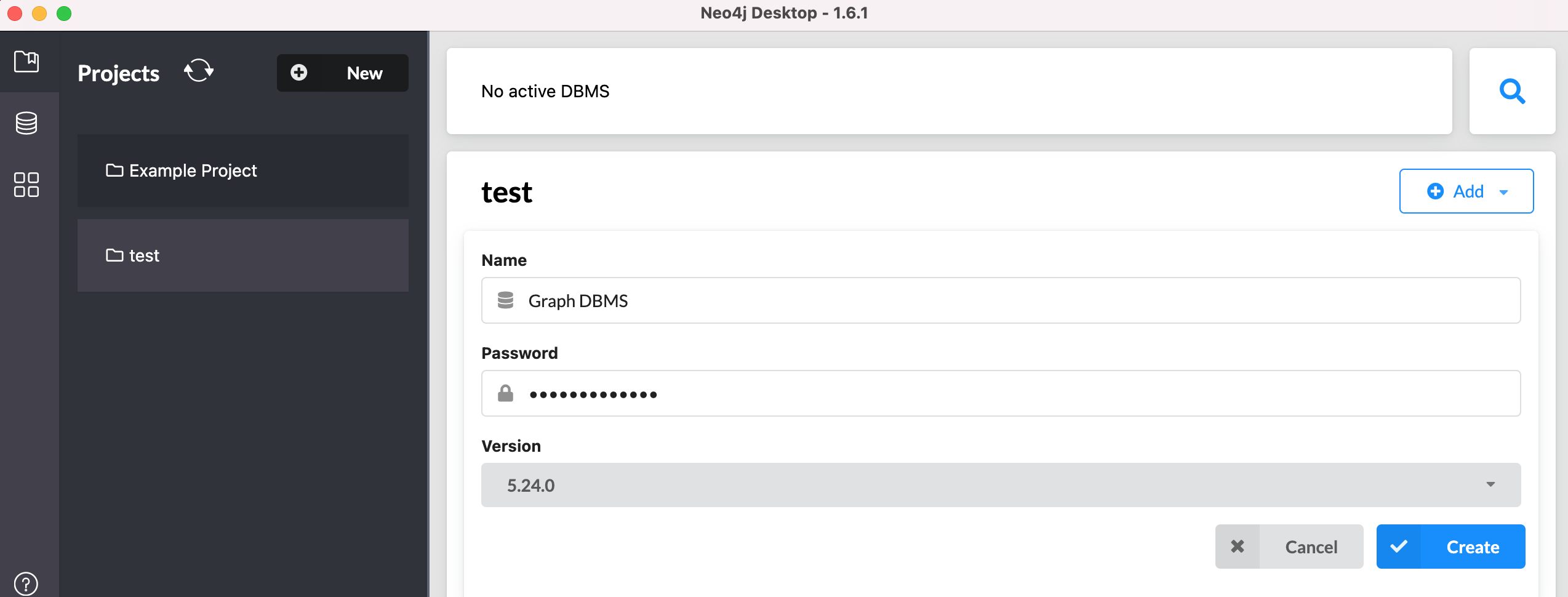
新建完成后,即可连接这个 Local DBMS,连接成功后即可在顶部矩形框输入并执行 Cypher Query 了:
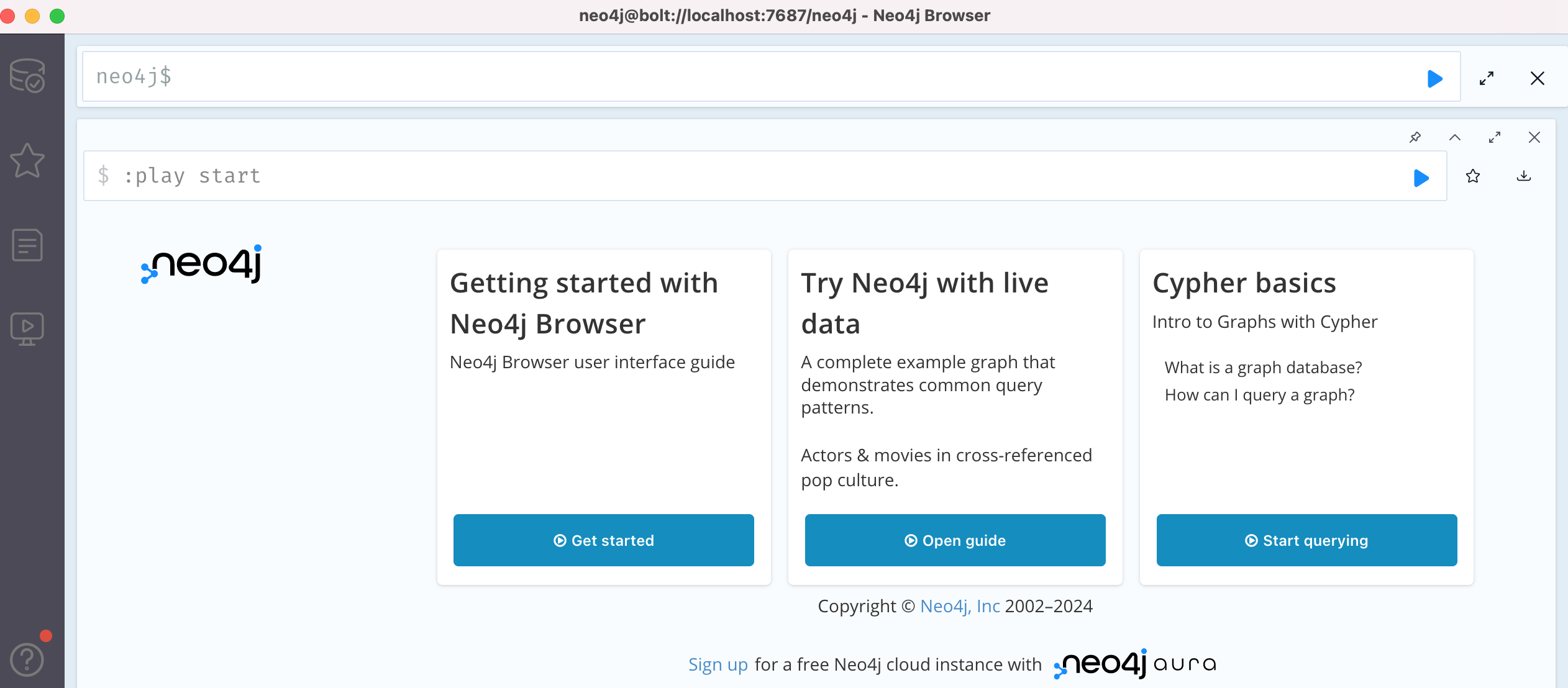
2.2 数据插入
下面使用 CREATE 语句创建稍多一点的「演员 - 参演 -> 电影」的数据:
CREATE
(a1:Actor {name: "吴京", nationality: "中国", yearOfBirth: 1974}),
(a2:Actor {name: "卢靖姗", nationality: "中国", yearOfBirth: 1985}),
(m1:Movie {name: "战狼 Ⅱ", releasedAt: 2017}),
(m2:Movie {name: "太极宗师", releasedAt: 1998}),
(m3:Movie {name: "流浪地球 Ⅱ", releasedAt: 2023}),
(m4:Movie {name: "我和我的家乡", releasedAt: 2020}),
(a1)-[:ACTED_IN {role: "冷峰"}]->(m1),
(a1)-[:ACTED_IN {role: "杨昱乾"}]->(m2),
(a1)-[:ACTED_IN {role: "刘培强"}]->(m3),
(a2)-[:ACTED_IN {role: "Rachel"}]->(m1),
(a2)-[:ACTED_IN {role: "EMMA MEIER"}]->(m4)
2.3 简单数据查询
数据插入完成后,使用如下语句将数据库中的模式进行图形化表示:
CALL db.schema.visualization()

然后查询「演员 - 参演 -> 电影」模式的所有演员和电影:
MATCH (a:Actor)-[:ACTED_IN]->(m:Movie)
RETURN a, m
其图形化返回结果如下:

接下来实现一个稍微复杂点的查询:查询参演了电影《战狼 Ⅱ》的演员还参演了哪些电影:
MATCH (Movie {name: "战狼 Ⅱ"})<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(m:Movie)
RETURN a.name AS actorName, m.name as movieName
其表格化返回结果如下:
| actorName | movieName |
|---|---|
| 吴京 | 太极宗师 |
| 吴京 | 流浪地球 Ⅱ |
| 卢靖姗 | 我和我的家乡 |
2.4 复杂数据查询
前面的查询均比较简单,下面进行一些稍微复杂点的查询。
开始前,让我们植入一组「用户 - 评分 -> 电影」的数据。前面的数据植入是直接使用 CREATE 语句实现的,下面尝试使用另一种方式:从 csv 文件导入。
用户对电影评分的数据文件 ratings.csv 的内容如下:
user,movie,rating
夏天,战狼 Ⅱ,9
珊珊,战狼 Ⅱ,9
大鹏,战狼 Ⅱ,8
朵朵,战狼 Ⅱ,8
乐乐,战狼 Ⅱ,8
三月,战狼 Ⅱ,9
夏天,流浪地球 Ⅱ,8
珊珊,流浪地球 Ⅱ,8
大鹏,流浪地球 Ⅱ,7
朵朵,流浪地球 Ⅱ,8
乐乐,流浪地球 Ⅱ,8
三月,流浪地球 Ⅱ,6
将上述文件置于 Neo4j 指定目录后,使用如下语句读取 csv 文件中的行,然后针对每行数据进行 User 创建、Movie 查找,以及「用户 - 评分 -> 电影(User - RATED -> Movie)」关系的创建。
LOAD CSV WITH HEADERS FROM 'file:///ratings.csv' AS row
MERGE (u:User {name: row.user})
WITH u, row
MATCH (m:Movie {name: row.movie})
CREATE (u)-[:RATED {rating: toInteger(row.rating)}]->(m);
如上语句的 MERGE 关键字相当于 CREATE or MATCH,即在没有数据时进行创建,有数据时进行匹配。
「用户 - 评分 -> 电影」数据插入完成后,即可使用如下语句进行查询了:
MATCH (u:User)-[:RATED]-(m:Movie)
RETURN u, m
「用户 - 评分 -> 电影」的图形化返回结果如下:

像 SQL 一样,Cypher 里也可以使用聚集函数,下面即是查询平均分最高的电影的语句:
MATCH (u:User)-[r:RATED]->(m:Movie)
RETURN m.name AS movie, avg(r.rating) AS avgRating
ORDER BY avgRating DESC
LIMIT 1
其表格化返回结果如下:
| movie | avgRating |
|---|---|
| 战狼 Ⅱ | 8.5 |
接下来见识一下图数据库的威力,我们尝试查找一下「吴京」与「卢靖姗」这两个演员之间的最短路径:
MATCH (a1:Actor {name: "吴京"})
MATCH (a2:Actor {name: "卢靖姗"})
MATCH p = shortestPath((a1)-[*..10]-(a2))
RETURN p
上述语句首先找出了两个演员 a1 与 a2,然后使用 shortestPath 函数查找 a1 与 a2 之间的最短路径,该函数传入的一个参数是 (a1)-[*..10]-(a2),* 表示不限两个节点连接起来所跨越路径的类型,没有箭头说明不限连接方向,而为了避免跨度太大造成无尽的搜索,..10 表示搜索深度不要超过 10 层。需要注意的是最后若有多个相同深度的结果,只会返回其中之一。
上述语句的图形化返回结果如下:

可以看到,「吴京」与「卢靖姗」都参演过《战狼 Ⅱ》是他们之间的最短路径。
接下来使用 shortestPath 查询一下评分用户「大鹏」和演员「吴京」之间有没有一个最短路径:
MATCH (u:User {name: "大鹏"})
MATCH (a:Actor {name: "吴京"})
MATCH p = shortestPath((u)-[*..10]-(a))
RETURN p
得到的图形化返回结果如下:

可以看到,「大鹏」评分了《战狼 Ⅱ》,而「吴京」参演了《战狼 Ⅱ》,这就是他们之间最「近」的联系。
3 小结
综上,本文首先介绍了 Neo4j 中的概念和基础知识,然后在本地下载安装「Neo4j Desktop」,并插入实例数据,对 Neo4j 的 Cypher Query 进行了初步使用。总的来说,Neo4j 是一个有趣的图数据库,其更高级一点的特性值得更进一步的探索。
参考资料
[1] YouTube: Training Series - Introduction to Neo4j - https://www.youtube.com/watch?v=YDWkPFijKQ4
[2] Neo4j: What is a graph database - https://neo4j.com/docs/getting-started/graph-database/
[3] Neo4j: What is Neo4j? - https://neo4j.com/docs/getting-started/whats-neo4j/
[4] Neo4j: What is Cypher - https://neo4j.com/docs/getting-started/cypher/
[5] Neo4j: Desktop Download - https://neo4j.com/download/
[6] Neo4j: Importing CSV data into Neo4j - https://neo4j.com/docs/getting-started/data-import/csv-import/

相关文章
评论
 正在加载评论......
正在加载评论......